Contenido x
- Cómo empezar a usar Airtable
- Introducción a los aspectos básicos de Airtable
- Cómo comunicarse con el equipo de soporte de Airtable
- Pantalla de inicio de Airtable
- Glosario de terminología de Airtable
- Airtable technical requirements
- Diferencias entre las funciones de Airtable para escritorio y para móvil
- Atajos de teclado de Airtable
- Cómo usar Markdown en Airtable
- Adding descriptions in Airtable
- Finding Airtable IDs
- Automatizaciones de Airtable
- Descripción general de automatizaciones
- Guías de automatizaciones
- Guías de automatizaciones integradas
- Guías de automatizaciones en Airtable
- Linking existing records using automations
- Conditional groups of automation actions
- Repeating groups of Airtable automation actions
- Creating recurring records using automations
- How to delay Airtable automation runs
- Prevent automations from triggering by mistake
- Use automations to timestamp status updates
- Desencadenantes de automatizaciones
- Desencadenantes de Airtable
- Airtable automation trigger: When record matches conditions
- Airtable automation trigger: When a form is submitted
- Airtable automation trigger: When record created
- Desencadenante de automatización de Airtable: cuando se actualiza un registro
- Airtable automation trigger: When record enters view
- Desencadenante de automatización de Airtable: a una hora programada
- Airtable automation trigger: When webhook received
- Airtable automation trigger: When a button is clicked
- Airtable automation trigger: When email received
- Desencadenantes integrados
- Desencadenantes de Airtable
- Acciones de automatización
- Acciones en Airtable
- Acción de automatización de Airtable: enviar correo electrónico
- Airtable automation action: Create record
- Airtable automation action: Update record
- Airtable automation action: Find records
- Airtable automation action: Sort list
- Acción de automatización de Airtable: ejecutar un script
- Airtable automation action: Generate with AI
- Acciones integradas
- Airtable automation actions: Slack
- Airtable automation actions: Google Workspace
- Airtable automation action: Send MS Teams message
- Airtable automation actions: Outlook
- Airtable automation actions: Jira Cloud
- Airtable automation actions: Jira Server / Data Center
- Airtable automation actions: Salesforce
- Airtable automation action: Create post in Facebook Pages
- Airtable automation actions: GitHub Issues
- Airtable automation action: Hootsuite post
- Airtable automation action: Send Twilio SMS
- Acciones en Airtable
- Bases de Airtable
- Using Airtable Cobuilder
- Descripción general de las bases de Airtable
- Creating and duplicating bases in Airtable
- Structuring your Airtable bases effectively
- Moving Airtable bases between workspaces
- Tables in Airtable
- Crear enlaces para compartir bases de Airtable
- Importing third-party data into Airtable
- Uso de las perspectivas
- Troubleshooting Airtable base performance
- Versiones beta de Airtable
- Colaboración en Airtable
- Asistencia de Airtable Enterprise
- Información general
- External badging in Airtable
- Creating and using Airtable components
- Ask an Expert beta overview
- Data residency at Airtable
- Descripción general de los grupos de usuarios en Airtable
- API de Enterprise de Airtable
- Creating and managing data retention policies in Airtable
- eDiscovery APIs in Airtable
- Airtable and data loss prevention
- Acceder a los registros de auditoría de Enterprise en Airtable
- Configuración de Jira Server/Data Center para conectarse con Airtable
- Panel de Administración de Enterprise
- Descripción general del panel de administración de Enterprise
- Usuarios: panel de administración de Enterprise en Airtable
- Detalles del usuario en el panel de administración de Airtable
- Grupos: panel de administración de Airtable
- Espacios de trabajos: panel de administración de Enterprise de Airtable
- Bases: panel de administración de Enterprise en Airtable
- Interfaces: Panel de administración de Enterprise en Airtable
- Data sets - Airtable admin panel
- Managed apps - Airtable admin panel
- Components - Airtable admin panel
- Informes: panel de administración de Enterprise en Airtable
- Airtable admin panel settings
- Guía práctica de Enterprise
- Gestionar a los admins de Enterprise en el panel de administración
- Uso de organizaciones
- Organizational branding for apps in Airtable
- Enterprise Hub in Airtable
- Enterprise Hub : Org unit assignment with user groups
- Desactivar, retirar el acceso y reactivar usuarios desde el panel de administración
- Gestionar el acceso de usuario a espacios de trabajo y bases
- Airtable Enterprise Key Management
- Custom terms of use
- SSO en Enterprise
- Información general
- Extensiones de Airtable
- Descripción general de las extensiones
- Extensiones por Airtable
- Extensiones integradas
- Campos de Airtable
- Descripción general de los campos
- Archivo adjunto
- Campos basados en fecha
- Fórmula
- Empezar a usar fórmulas
- Fundamentos de fórmulas
- Soluciones frecuentes: principiante
- Soluciones habituales: intermedias
- Soluciones habituales: avanzado
- Campo de texto largo
- Campos de registros vinculados
- Campos con números
- Otros campos
- Campos de compilación, búsqueda y recuento
- Campos de selección y colaborador
- Integración con Airtable
- API
- Getting started with Airtable's Web API
- Crear tokens de acceso personal
- Airtable Webhooks API Overview
- Service accounts overview
- API web de Airtable: usar filterByFormula o parámetros para ordenar
- Airtable API Deprecation Guidelines
- Airtable API: Common troubleshooting
- Managing API call limits in Airtable
- Enforcement of URL length limit for Web API requests
- Servicios de integración
- Third-party integrations via OAuth overview
- Troubleshooting disconnected OAuth integrations in Airtable
- Options for integrating with Airtable
- Third-party integrations - Common troubleshooting
- Low-code integrations - Common troubleshooting
- Integrating Airtable with external calendar applications
- Visualizing records from Airtable in Tableau
- Visualizing Airtable records in Microsoft Power BI & Power Query
- Integrating HubSpot with Airtable
- Using Zapier to integrate Airtable with other services
- Using Zapier's Multi-Step Zaps to find and update records
- Using IFTTT to integrate Airtable with other services
- Integrating with AWS Lambda & DynamoDB
- Herramientas para desarrolladores
- API
- Diseñador de Interfaces de Airtable
- Descripción general
- Diseños de página
- Elementos
- Adding and removing elements in interfaces
- Adding layouts to interfaces
- Formatting elements in interfaces
- Interface element: Button
- Interface element: Calendar
- Interface element: Chart
- Interface element: Filter
- Interface element: Gallery
- Interface element: Grid
- Interface element: Kanban
- Interface element: Number
- Interface element: Record picker
- Interface element: Text
- Interface element: Timeline
- Aprendizaje y recursos
- Gestión de Airtable
- Política de Airtable
- Registros de Airtable
- Sincronización de Airtable
- Vistas de Airtable
- Espacios de trabajo de Airtable
- Impresión
- Compartir
- OscuroLigero
- PDF
Contenido
Getting started with selective sync in HyperDB
- Actualizado en 08 Jan 2025
- 4 Minutos para leer
- Impresión
- Compartir
- OscuroLigero
- PDF
The content is currently unavailable in Spanish. You are viewing the default English version.
Resumen del artículo
¿Te ha resultado útil este resumen?
Gracias por sus comentarios
Enterprise Scale only | |
Owners/Creators - To create or update synced tables, you'll need to have creator permissions in the base where you are setting up the sync. | |
Platform(s) | Web/Browser, Mac app, and Windows app |
Related reading |
|
Understanding selective syncing
Selective sync is a new way to link records on an as-needed basis, to a massive dataset powered by Airtable’s HyperDB feature. You can search over millions of records without slowing down performance.
This is done by syncing each record to your table as it is linked, instead of the typical way that sync works, which would bring in all records from a synced data set.

For example:
To get started, you need to have an existing table that you want to link to a larger set of data. In the diagram below, Zelos Inc. has an existing “Support tickets” table, and wants to link the “Requester” field to the HyperDB-backed data set “All users.”
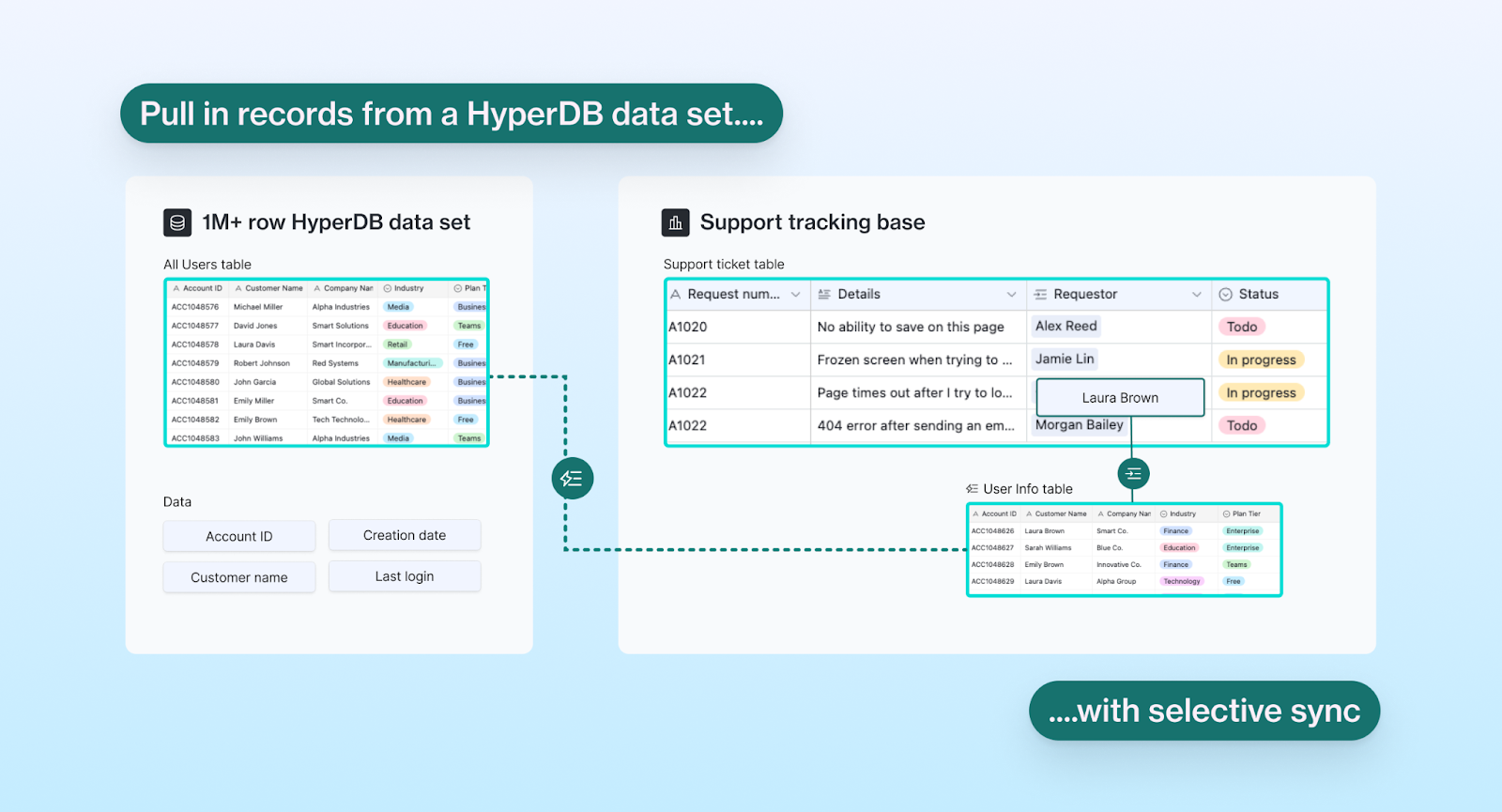
They would then add the data set “All users” as a new table named “User info” by choosing the “All users” data set from the data library.
During the setup process, they will use selective sync to bring in the user data, choosing to link it to the “Support requests” table and “User info” linked record field.
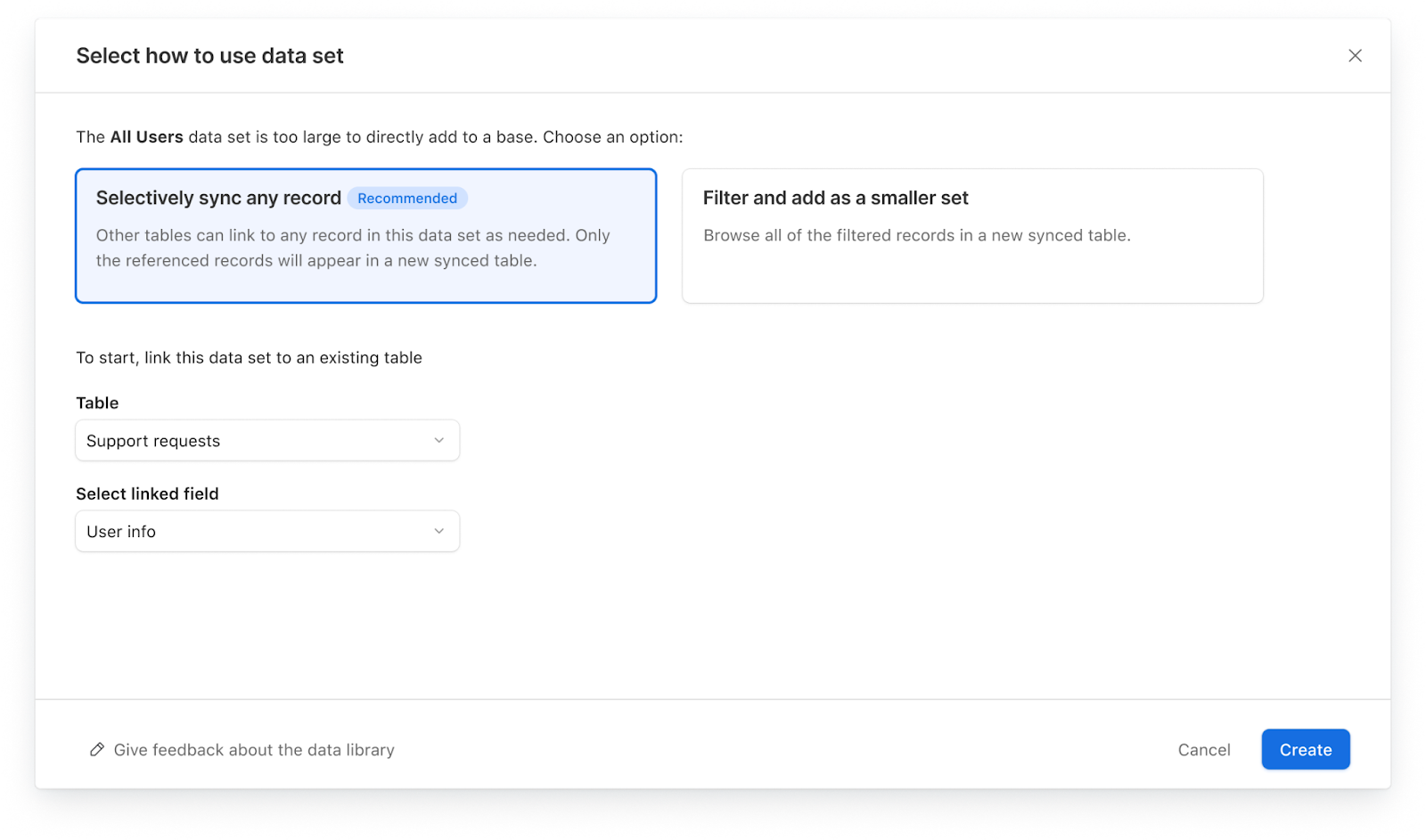
Once the “All users” data set has been connected to the selectively synced table, you can search for any record with the linked record picker. Support tickets can then be associated with any user in the “All users” dataset. The selectively synced “User info” table will only display a subset of users that have been actively linked to tickets.
.png)


.png)
Note
Once a record has been selectively synced into the base, it will remain there, even if the linked record is removed from the specific support ticket.
Using selective syncing versus filtering
There are two ways you can add a HyperDB data set to a table: selective sync and filtering. Selective sync is the recommended way to add HyperDB data sets to a table, but here are examples of when each would be relevant.
Selective sync | Filtering | |
|---|---|---|
Best for | Performance - Only add selected records to a base to prevent bogging down your base’s performance with too many (unneeded) records. | Completeness - Having all of the data in the table. This may help for referencing information, but can also slow down base performance significantly. |
Linked record relationships | Linking a data set to other tables in the base is important. | I don’t need linked records, I just need to see all the records. |
Updates | Data will get dynamically updated from the HyperDB data set. | Data will get dynamically updated from the HyperDB data set. |
Upon creation | A new blank table will be created. As records are linked to the HyperDB data set, they will populate in this new table. | A new table will be created with all of the filtered records. |
General example | I want to bring in only information about “Ratatouille”, “Cars”, and “Up” from my “Movies” dataset. | I want to bring in all the Pixar movies information between 2000-2010 from my “Movies” dataset. |
FAQs
What fields can I search by using the linked record picker?
HyperDB requires that each record have a unique primary key. Because that primary key is often not easy to read, we’ve introduced the concept of a “search field” for HyperDB. This is configured by the admin and published as part of the data set.

If the search field is visible in the linked record picker (the field cannot be hidden), the linked record picker will allow you to search by either the primary field or the search field.

As records are added with the linked record picker, they’ll be added to the selectively synced table.
How can I use automations to help with linking?
You can use an automation to link to any record in a selectively synced table as long as you know the unique ID for the record. You can do so by triggering an Update record action in the local table that links to the selectively synced dataset. In this way, if you update a specific linked record field with the unique ID from the larger dataset, then it will get synced into the base automatically.
Can I edit records in a selectively synced table?
No, records can not be altered from how they appear in the original data set.
Will I have to follow base limits using filtering?
Yes, before a data set can be added into a base, it must be filtered down to our records limit of 250,000 records.
Can I search through any column in the linked record picker using selective sync?
No, you’ll be able to search through two columns (primary key and an additional search key) in order to find records.
Will I be able to preview the larger data set a selective sync pulls from?
You can preview the data set using the linked record picker to scroll through records, otherwise, there is no way to “preview” the entire data set.
¿Te ha sido útil este artículo?
¡Gracias por sus comentarios! Nuestro equipo se pondrá en contacto con usted
¿Cómo podemos mejorar este artículo?
Sus comentarios
Comentario
Comentario (Opcional)
Límite de caracteres : 500
Por favor, introduzca su comentario
Correo electrónico (Opcional)
Correo electrónico
Introduce un correo electrónico válido
