Plan availability | Enterprise Scale |
Permissions |
|
Platform(s) |
|
Related reading |
HyperDB is a powerful feature that allows Enterprise Scale customers to work with large datasets (up to 100M rows) in a new storage layer outside of a base. HyperDB tables can be populated from CSV files or connected directly to other cloud sources, making it easy to bring your important data into Airtable. Builders can access the data stored in HyperDB by using published data sets in the data library. Features like on-demand sync allow your organization to operationalize massive datasets across your complex workflows.
HyperDB prerequisites
Before using HyperDB, ensure you have:
An Enterprise Scale plan
Enterprise Admin or Integration Admin permissions
Data in CSV format or access to Snowflake, Salesforce, or other supported integrations (if using external integrations)
A primary key field that is unique per row in your dataset
Data with no more than 100M rows
HyperDB is not yet available for our European data residency customers
Creating a new HyperDB table
To create a HyperDB table:
Open your admin panel.
Click HyperDB.
Click Add table.
Enterprise Hub only - Select the org unit you want to use.
You’ll then choose whether to import data one time (via a CSV file upload) or set up a recurring import.
CSV file imports are covered in this section.
Instructions for setting up recurring integrated imports vary by import type.
Configuring CSV files for one time imports
After clicking the Local CSV file option, click Next.
Drop your CSV file or browse your computer and select your preferred file. Click Upload 1 file.
Note that you are only able to upload a single file.
You will then be brought to a preview of the table that will be created from the CSV. You’ll need to map out the schema for your table.
The system will attempt to detect appropriate field types, but you can modify these as needed by clicking the dropdown icon on each field that needs adjusting.
You can also hop ahead to the “Review field mapping” step and review field mappings and our automatic suggestions.
* Important: Once you choose field types, you cannot change them in HyperDB, so ensure the field types you’ve selected are the best fit for your organization’s needs.
Select a primary field (unique ID field).
Optionally, select a secondary field to help with searching.
This should be human-readable and will enable users to perform friendly name searches when linking records via on-demand sync.
Review field mapping once more and then click Continue.
Next, enter a name and description for your HyperDB table. When your import contains one or more date fields, you’ll need to set a timezone for those date fields as well.
Click Save. Wait for your dataset to process. You can return to the specific HyperDB table’s page to check the status of your import. This may take some time depending on the size of your table.
Publishing data sets to your data library
To enable usage of HyperDB table data in bases and apps across your organization, you will need to publish a subset of the data. Filtering is an important step because many HyperDB tables will exceed the storage limits of individual bases. To create data sets from a HyperDB table:
If you aren’t already in admin panel, open your admin panel and click HyperDB.
Under the “Table” column, click the name of the table that you want to publish as a data set.
Scroll down to the “Published data sets” section and click Published data sets.
Click Create data set.
Choose which fields you want included in the data set by clicking the checkbox next to each field’s name. You can also click Select all and uncheck the box next to any fields you don’t want to include if that is an easier option. When you are finished, click Next.
(Optional, but encouraged) Next, you will define filters to scope your data set to a specific slice of the larger HyperDB table dataset.
Click + Add condition to get started with filtering. More information about filtering in Airtable is available here.
You can also review how many records are in the data set in the lower-left corner of the window. You can publish a data set of any size, but we will tell you if the data set is larger than what can be directly synced into a base.
Once you’ve configured your preferred filters, click Next.
Next, you’ll set sync behavior. After selecting an option, click Next. There are two options to choose from:
(Recommended) The default setting is Block syncs to other bases. If you choose not to allow downstream syncs, end users won't be able to "daisy-chain" syncs to other bases.
You can also choose to Allow syncs to other bases. Bases that add this data set can then sync the imported data out to other bases.
Note
The "Allow syncs to other bases" setting controls downstream syncs — whether a base can pass this HyperDB data along to other bases. It doesn't enable two-way sync back to HyperDB. Edits made in a base never sync back to the HyperDB source table.
On the next screen, there are several settings to configure:
Enter a name and description for the data set.
Choose the “Data set owner.” By default, this will be you, the person setting it up, but you can select another user if necessary.
Define the audience. This can be specific user groups or org units (Enterprise Hub only), or you can make it available to everyone at your organization.
Once you are done configuring the data set, click Publish.
Viewing and managing published data sets
To view or manage published data sets:
Open your admin panel.
Click HyperDB.
All published data sets from a HyperDB table are displayed here.
Click the name of a HyperDB table that you want to view or manage.
More details to see which bases are syncing your published data.
(Optional): Click the … icon at the end the data data you modify.
Using HyperDB in a base
After creating a HyperDB table and a published data set, collaborators can access it through the data library in their bases. To use a HyperDB table in a base:
Open your Airtable home screen.
Open the base where you want to use HyperDB data.
Click + Add or import.
Builders who are in the admin's defined audience can find published data sets in the data library.
Locate and select your HyperDB data located under the “Add from data library” section.
You will likely need to click the xx more date sets > option. This will open a window where you can browse or search for a specific data set by name.
After selecting your data, a preview window opens.
Click Add this data.
There are two primary ways to use a HyperDB dataset in a base, each with its own settings to adjust:
Pull records in on-demand - All records from the published HyperDB dataset will be available to choose from a linked record field. The table you are syncing will only show records that are actively linked. For this option, you’ll need to:
Select an existing table where a new linked record field will be created.
Select a linked field that will connect records in the HyperDB dataset to another table. You can either allow Airtable to create a new linked record field by clicking the + Create new field option or select an existing field from the table you selected in the previous step. Note that this will convert the existing field to be a linked record field type if it isn’t already a linked record field type.
When records are unlinked, you’ll toggle whether or not that will “Automatically delete records from synced table.” That is to say, if the records aren’t automatically deleted, then they will remian in the synced table.
Note
When configuring match/link settings for an on-demand synced HyperDB table, ensure your matching field is the table's primary field. Selecting a non-primary field as the match key is not supported and may cause the sync configuration to fail or behave unexpectedly.
Filter and add as a smaller set - Alternatively, you can set up one or more record filters that will create a synced table that only contains the records matching your filter conditions. This a good option when you know that a certain subset of records are the only ones that will ever be relevant to the base you are working in.
Select the Filter and add as a smaller set option.
Add one or more conditions or condition groups. Learn more about filtering Airtable records in this support article. For larger datasets, be sure to pay attention to the number of records that will be added into the table based on the filters you have added. We will warn you when the dataset is over the record limits for a table/base. In those cases, you’ll need to add additional filters to pare down the number of records or consider using the “On-demand” option discussed above.
No matter the way you select to use the HyperDB dataset, you’ll click Create when you have finished configuring the settings to your preferences.
Adjusting existing HyperDB tables from admin panel
For all of the options listed below:
Open your admin panel.
Click HyperDB.
Search or browse for a table and then click the table’s name under the “Table” column.
Adding a field to an existing HyperDB table
Click the Edit fields dropdown button.
Click Add field.
Give the field a name and select a field type.
Click Save.
Removing a field from an existing HyperDB table
Click the Edit fields dropdown button.
Click Delete fields.
Click the checkbox next to the name of one or more fields.
Click Delete.
When deleting fields you will see a warning of which bases are syncing this data into their bases.
You might want to consider contacting the owner of those bases before making changes to the data set.
Click Delete again.
Updating the HyperDB table with a new CSV
Click the … button next to the current name of the dataset.
Click Update table from CSV.
Choose whether to Update existing table or Overwrite table.
Click Next.
Drag and drop the new CSV file and click Upload 1 file.
When overwriting a table, the message “This step is irreversible” will appear, to remind you that the previous dataset will not be accessible any longer.
After the file has finished uploading, click Confirm.
Any new fields present in the updated CSV will be added to the table.
Any field re-ordering present in the updated CSV will be respected by the updated table.
Renaming a HyperDB table
Click the … button next to the current name of the dataset.
Click Rename table.
Adjust the name and click Save.
Deleting a HyperDB table
Click the … button next to the current name of the dataset.
Click Delete table.
A confirmation modal will appear with the message “This HyperDB table cannot be restored. All data sets associated will be deleted and downstream syncs will break.”
If you are sure you want to delete the HyperDB dataset, then type the name of the table in the appropriate box and then click Confirm.
HyperDB limitations and dependencies
HyperDB tables require the Enterprise Scale plan.
Data must be under 100M rows.
Cannot change field types after table creation.
Single select fields are limited to 1,000 options.
Cannot remove single select options after creating a HyperDB table.
Cannot add or remove fields in tables that use native integrations like Salesforce or Snowflake.
Number fields will default to only show whole integers. To remedy this, update the field formatting in the base to show the desired decimals (e.g. 2 places).
Matching and linking records in an on-demand (selectively-synced) HyperDB table is only supported when matching on the table's primary field. Matching or linking on a non-primary field is not supported for on-demand sync configurations.
When using on-demand (selective) sync, automation-based linking can only link a single matching HyperDB-backed record at a time by its ID. There is no built-in way to automatically link a record to multiple matching records in the HyperDB-backed dataset (a one-to-many match). Automations must be built to handle records individually, or matches must be linked manually.
Two-way sync isn't supported. HyperDB syncs are one-directional (HyperDB to base), so edits made in a base don't sync back to the HyperDB source table.
FAQs
What is the limit to the number of HyperDB tables I can create?
5 HyperDB tables are included with Enterprise Scale plans. Additional tables are available as a paid add-on via our sales team.
Can I update my HyperDB table automatically?
Currently, there's no automated way to keep CSV-based HyperDB tables up to date. However, you can use the API to update data or connect directly to Snowflake or Salesforce for regular refreshes. For CSV-based tables, you can replace all data or upload a differential update.
Can I access HyperDB data through the API?
Yes, HyperDB tables can be accessed through the Airtable API.
I’m having an issue with HyperDB, how do I contact support?
Contact Airtable Support by clicking ![]() on the lower right corner.
on the lower right corner.
Within the body of your request, please include the HyperDB Table ID which is helpful for our team to troubleshoot potential issues. This ID can be found by following these steps:
Navigate to your admin panel on a browser.
Click the HyperDB tab.
Search or browse for the table where you are experiencing issues and click the table name to view more details.
In your browser’s address bar copy the last portion of the URL from
edton so that you have the full ID that will look like thisedtxxxxxxxxxxxxxx.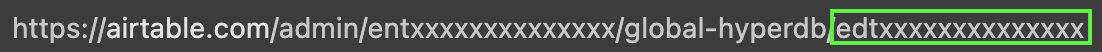
Include that ID in your message to support.
When does a HyperDB table sync in nightly mode?
For HyperDB tables connected to Snowflake or Salesforce, the integration runs once every 24 hours on a nightly schedule. Admins can also trigger a manual import at any time from the admin panel). For Databricks-backed HyperDB tables, the run cadence is governed by the "Update frequency" set when the table was configured. If you need to schedule downstream tasks to run after a HyperDB refresh, the most reliable approach is to key off the data's actual update (for example, a "last synced/last modified" signal) rather than a fixed clock time, since the exact minute can vary and isn't guaranteed to the precision needed for tight scheduling. Admins who need a guaranteed ordering can manually trigger the import and then run dependent tasks.
What's the best way to combine HyperDB data with additional/historical data?
There's no built-in way to combine a HyperDB dataset with extra data within the HyperDB layer. Where possible, the recommended approach is to combine your live and historical data at the source (in the warehouse/source the HyperDB table imports from) before it syncs in — then HyperDB brings it in as a single unified table. The alternative some teams use — creating an add-on sync table that merges an extra table with the HyperDB dataset — works, but it produces a different dataset type that loses HyperDB-specific features.
Can I use two-way sync with HyperDB?
No, two-way sync isn't supported with HyperDB. HyperDB syncs are one-directional, data flows from HyperDB into your base, but edits you make in the base don't sync back to the HyperDB source table. This is different from Airtable's standard base-to-base sync, where the "Allow edits from other bases" setting can push changes back to the source. That setting isn't available for HyperDB data.
To change the underlying data, update it at the source (for example, your CSV upload, Snowflake, Salesforce, or Databricks connection), and the next sync brings those changes into your base. For more on how records behave in a synced on-demand table, see our Using HyperDB in Airtable article.